Quick Overview: Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter.: Animation ...
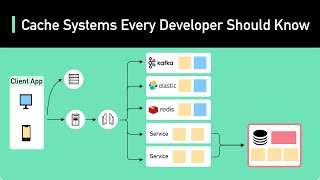
Caching Explained Faster Data Reduced - Detailed Overview & Context
Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter.: Animation ... In this first video in a three-part series, we'll explore what Ever wondered why some apps feel instant, while others are painfully slow? The difference is often just one thing: Are you curious about how Memcached works? Join us for a