Quick Overview: Try Voice Writer - speak your thoughts and let AI handle the grammar: The KV In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV Don't like the Sound Effect?:* *LLM Training Playlist:* ...
Key Value Cache From Scratch - Detailed Overview & Context
Try Voice Writer - speak your thoughts and let AI handle the grammar: The KV In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV Don't like the Sound Effect?:* *LLM Training Playlist:* ... We just launched the all-in-one tech interview prep platform, covering coding, system design, OOD, and machine learning. Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ... Assaf Eisenman, Stanford University; Asaf Cidon, Stanford University and Barracuda Networks; Evgenya Pergament and Or ...
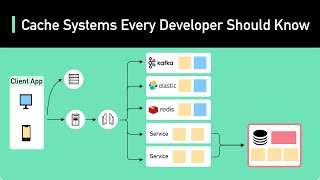
In this comprehensive crash course, I'll break down everything you need to know about This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ... Use the special link (or code: MATRIX200) to try Redis Enterprise Cloud to get a $200 credit, become part ... In this video, I explore the mechanics of KV Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter.: Animation ... As llm serve more users and generate longer outputs, the growing memory demands of the
Same prompt. Same model. The first call costs $1.00. The second costs $0.05. Same words — 20× cheaper. The reason isn't a ... Ever wondered how large language models like GPT respond so fast without recomputing everything from








![KV Caching: Speeding up LLM Inference [Lecture]](https://i.ytimg.com/vi/_quDGLpNols/mqdefault.jpg)