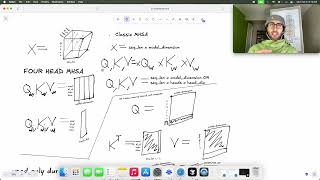
Short Overview: Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? Every modern LLM hides one trick that makes token generation 10–100× faster: the ...
Kv Cache Explained In 3 11258 -
Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? Every modern LLM hides one trick that makes token generation 10–100× faster: the ... Try Voice Writer - speak your thoughts and let AI handle the grammar: The
Important details found
- Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations?
- Every modern LLM hides one trick that makes token generation 10–100× faster: the ...
- Try Voice Writer - speak your thoughts and let AI handle the grammar: The
Why this topic is useful
Readers often search for Kv Cache Explained In 3 11258 because they want a clearer explanation, related examples, and a practical way to continue exploring the topic.
Sponsored
Frequently Asked Questions
How should readers use this information?
Use it as a starting point, then open related pages for more specific details.
What should readers check next?
Readers should check related pages, official references, or updated sources when details matter.
Why are related topics included?
Related topics help readers compare nearby references and understand the broader subject.
Visual References









Sponsored