Quick Overview: Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce ... In this video, we look into SmoothQ Algorithm and Paper: Paper: Pseudocode Open Source ... SmoothQuant - Accurate and Efficient Post-Training Quantization for Large Language Models
Smoothquant - Detailed Overview & Context
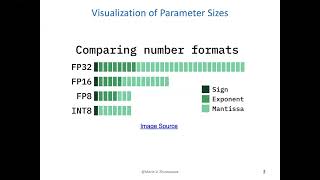
Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce ... In this video, we look into SmoothQ Algorithm and Paper: Paper: Pseudocode Open Source ... SmoothQuant - Accurate and Efficient Post-Training Quantization for Large Language Models Seminar date : 2024.07.05 # Seminar contents Paper Review Seminar # Paper Title Xiao, Guangxuan, et al. " Pseudo-lab (-lab ) EfficientLLM study Presenter: 김승우 Date: 2025/09/30 Paper: 00:00 Introduction to LLM Quantization 02:15 What is Quantization? 04:45 Post-Training Quantization (PTQ) vs. QAT 07:30 GPTQ ...
Are 1-bit LLMs the future of efficient AI? Or just a catchy Microsoft metaphor? In this video, we break down BitNet, the so-called ...







![[IDSL Paper Review] SmoothQuant](https://i.ytimg.com/vi/FjRJMzqAbgY/mqdefault.jpg)

![[Paper Review] SmoothQuant](https://i.ytimg.com/vi/dUzFAydJalM/mqdefault.jpg)


