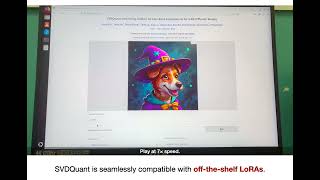
Quick Overview: On this AI Research Roundup, host Alex dives into a fascinating paper tackling model Can you really train a large language model in just A new post-training training quantization paradigm
Svdquant Efficient 4 Bit Diffusion - Detailed Overview & Context
On this AI Research Roundup, host Alex dives into a fascinating paper tackling model Can you really train a large language model in just A new post-training training quantization paradigm Run massive AI models on your laptop! Learn the secrets of LLM quantization and how q2, q4, and q8 settings in Ollama can save ... Welcome to DigitalBrainBase! In this video, we're diving deep into the concept of quantization and exploring how it's ... Try Voice Writer - speak your thoughts and let AI handle the grammar: Four techniques to optimize the speed ...
ICLR 2024에 spotlight로 accept된 EfficientDM: The first 500 people to use my link will receive 20% off their first year of Skillshare! Get started today! Post-Training Quantization on Diffusion Models (CVPR 2023) Download Tanka today and enjoy 3 months of free Premium! You can also get $20 / team