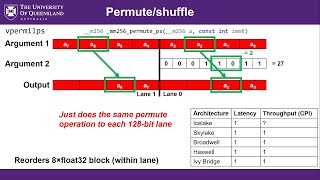
At a Glance: We're told modern compilers automatically optimize our loops for SIMD, but the reality is much more fragile. In this video from the Intel HPC Developer Conference at SC15, Kevin O'Leary from Intel presents:
011e Vectorized Computing -
We're told modern compilers automatically optimize our loops for SIMD, but the reality is much more fragile. In this video from the Intel HPC Developer Conference at SC15, Kevin O'Leary from Intel presents: Well you guys asked for it, and it's up there in complexity for this channel!
Important details found
- We're told modern compilers automatically optimize our loops for SIMD, but the reality is much more fragile.
- In this video from the Intel HPC Developer Conference at SC15, Kevin O'Leary from Intel presents:
- Well you guys asked for it, and it's up there in complexity for this channel!
- Take the Deep Learning Specialization: Check out all our courses: Subscribe to ...
Why this topic is useful
This format is designed to help readers move from a broad question into more specific pages without losing context.
Sponsored
Frequently Asked Questions
What is this page about?
This page summarizes 011e Vectorized Computing and connects it with related entries, references, and supporting context.
Is the information always complete?
Not always. Some topics may need verification from official or primary sources.
How should readers use this information?
Use it as a starting point, then open related pages for more specific details.
Visual References








Sponsored