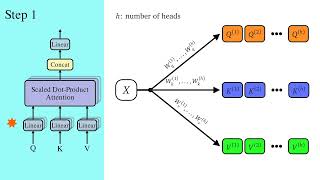
Quick Overview: In this video, I will first give a recap of Scaled Dot-Product Attention, and then Transformer implementation from scratch ( Check out Sebastian Raschka's book Build a Large Language Model (From Scratch)
A Dive Into Multihead Attention - Detailed Overview & Context
In this video, I will first give a recap of Scaled Dot-Product Attention, and then Transformer implementation from scratch ( Check out Sebastian Raschka's book Build a Large Language Model (From Scratch) What if I told you that the biggest breakthrough What if your AI could look at a sentence from 4 different angles — simultaneously? That's exactly what How do Transformers actually understand context? How does AI know what words relate