Quick Overview: Try Voice Writer - speak your thoughts and let In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Don't miss out! Join us at our next KubeCon + CloudNativeCon events in Mumbai, India (18-19 June, 2026), Yokohama, Japan ...
Kv Cache In Local Ai - Detailed Overview & Context
Try Voice Writer - speak your thoughts and let In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Don't miss out! Join us at our next KubeCon + CloudNativeCon events in Mumbai, India (18-19 June, 2026), Yokohama, Japan ... Ever wondered how large language models like GPT respond so fast without recomputing everything from scratch? In this video, I ... This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ... In this video we'll go through using persistent prompt
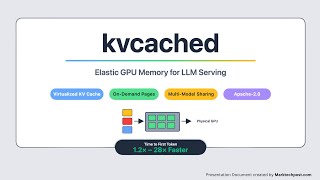
As llm serve more users and generate longer outputs, the growing memory demands of the Key-Value ( TurboQuant** is a recently published blog based on some published papers that will enable people on consumer devices to run ... GPUs get all the attention, but in inference, the real bottleneck is often memory, specifically the Google just revealed TurboQuant, an algorithmic breakthrough that dynamically compresses the Join us as we push our M3 Ultra Mac Studio to the edge with prompt





![KV Caching: Speeding up LLM Inference [Lecture]](https://i.ytimg.com/vi/_quDGLpNols/mqdefault.jpg)