At a Glance: The dirty little secret of Batch Normalization is its intrinsic dependence on the training batch size. Carnegie Mellon University Course: 11-785, Intro to Deep Learning Offering: Fall 2020 For more information, please visit: ...
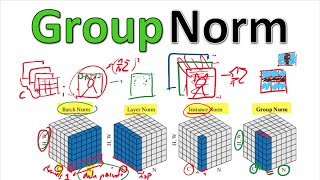
Lecture 49 Layer Instance Group Normalization -
The dirty little secret of Batch Normalization is its intrinsic dependence on the training batch size. Carnegie Mellon University Course: 11-785, Intro to Deep Learning Offering: Fall 2020 For more information, please visit: ... Carnegie Mellon University Course: 11-785, Intro to Deep Learning Offering: Fall 2019 For more information, please visit: ...
Important details found
- The dirty little secret of Batch Normalization is its intrinsic dependence on the training batch size.
- Carnegie Mellon University Course: 11-785, Intro to Deep Learning Offering: Fall 2020 For more information, please visit: ...
- Carnegie Mellon University Course: 11-785, Intro to Deep Learning Offering: Fall 2019 For more information, please visit: ...
- In this video, I review the different kinds of normalizations used in Deep Learning.
- Prabir Kumar Biswas, A renowned professor of Electronics and Electrical Communication ...
Why this topic is useful
This format is designed to help readers move from a broad question into more specific pages without losing context.
Frequently Asked Questions
What is this page about?
This page summarizes Lecture 49 Layer Instance Group Normalization and connects it with related entries, references, and supporting context.
Is the information always complete?
Not always. Some topics may need verification from official or primary sources.
How should readers use this information?
Use it as a starting point, then open related pages for more specific details.